디자인 패턴 - MVVM

앱을 개발하다 보면 자연스레 디자인 패턴이라는 단어를 접하게 됩니다. 디자인 패턴, 그게 뭘까요?
디자인 패턴이란 개발 과정에서 공통으로 발생하는 문제를 해결하기 위해 사용되는 패턴입니다. 이 말만 듣고는 어떤 문제를 해결하기 위함인지, 어떻게 적용되는지 알 수가 없죠. 우선 한 가지 예를 들어보겠습니다.
계산기 프로그램을 만들려고 하는데, 계산기 화면 구현과 사용자 입력, 입력값 처리 등의 모든 로직을 한 곳에 모두 작성했다고 합시다.
이후에 만약 계산기에 log를 추가해야 하는 요청이 들어와서 코드를 수정하려고 할 때, 눈앞이 캄캄해질 겁니다. 여기를 고치면 저기도 고쳐야 하고... 코드가 순식간에 지저분해집니다.
이때 필요한 것이 디자인 패턴입니다. 디자인 패턴을 적용해 코드의 여러 기능 및 로직을 분리해서 작성하면 유지보수에 도움이 되며 효율적인 코드 작성도 가능해집니다. 이런 디자인 패턴의 중요성은 코드의 복잡성과 의존성이 높은 규모가 큰 서비스를 개발할 때나, 다른 사람들과 협업할 때 더 부각됩니다. 주요 디자인 패턴들에는 MVC, MVP, MVVM 패턴이 있는데, 이 중 MVVM 패턴에 대해 얘기를 나눠보고자 합니다.
MVVM
MVVM 패턴은 아래의 세 가지로 구성되어 있습니다.
- Model
- View
- View Model
이름에서도 알 수 있듯 ModelViewViewModel 패턴인 거죠. 이제 각각의 역할과 동작 원리를 알아볼 텐데, 이해하기 쉽도록 View - View Model - Model 순으로 진행하겠습니다.
View
View는 앱의 UI와 관련된 부분입니다. 이름 그대로 사용자가 보는 화면 속 구조와 형태를 담당합니다. 사용자와의 상호작용을 통해 이벤트가 발생하면, 필요시 View Model을 호출합니다.
View Model
View Model은 View에 필요한 메서드 등이 구현된 곳으로, View의 UI에 있는 기능들이 정의되는 부분입니다. Model의 데이터를 가공해서 View에 전달하면 UI가 갱신됩니다. 오해하지 말아야 할 것은 View Model은 하나의 View에 종속되지 않으며, 필요시 여러 View에 참조될 수도 있습니다.
Model
Model은 앱에서 사용되는 데이터를 정의하고 다루는 부분이며, View Model과 마찬가지로 View로부터 독립적인 존재입니다.
동작
이를 정리하자면 앱은 아래의 흐름대로 동작합니다.
- 사용자의 입력이 View에 들어오면 View Model을 호출합니다.
- View Model은 필요한 데이터를 Model에 요청합니다.
- Model은 요청받은 데이터를 View Model에 응답합니다.
- View Model은 응답받은 데이터를 가공해서 저장합니다.
- View는 View Model과의 Data Binding으로 인해 갱신됩니다.
이제 MVVM 패턴이 무엇인지 대충 감은 잡힌 것 같은데, 이를 실제 개발에 적용하려니 아직 막막할 수 있습니다. 이해를 돕기 위해 MVVM 패턴이 적용된 간단한 Flutter 앱을 만들어 봅시다.
Flutter 앱에 적용
MVVM 패턴을 적용하여 간단한 메모 앱을 만들어 보려고 합니다. View, View Model, Model로 나누어 각각에 무엇이 들어가야 할지 대략적으로 정리해 보았습니다.
View
- 메모 페이지(memo_view.dart)
- 작성한 메모 목록
- 메모 추가, 삭제 버튼
- 메모 상세 페이지(memo_detail_view.dart)
- 제목, 내용 입력 칸
- 저장 버튼
View Model
- 메모 뷰 모델(memo_view_model.dart)
- 작성한 메모 목록 불러오기
- 메모 추가, 수정, 삭제
Model
- 메모 모델(memo.dart)
- 제목, 내용, 수정 날짜
파일 구조는 아래와 같습니다만, 개발자가 정하기 나름이므로 똑같을 필요는 없습니다.
- lib
- models
- memo.dart
- viewmodels
- memo_view_model.dart
- views
- memo_view.dart
- memo_detail_view.dart
- main.dart
- models
먼저 pubspec.yaml에 아래 패키지들을 설치해 줍니다. 버전은 2023년 5월 15일 기준 가장 최신 버전입니다.
provider: ^6.0.5
shared_preferences: ^2.1.1
intl: ^0.18.1
아래에 순서대로 코드를 나타내었습니다.
memo.dart
import 'package:intl/intl.dart';
class Memo {
final String title, content;
final DateTime time;
Memo({
required this.title,
required this.content,
required this.time,
});
static List<Memo> listFromString(
List<String> titlelist, List<String> contentlist, List<String> timelist) {
if (titlelist.isEmpty) return [];
return List.generate(
titlelist.length,
(idx) => Memo(
title: titlelist[idx],
content: contentlist[idx],
time: DateTime.tryParse(timelist[idx]) ?? DateTime.now(),
));
}
static List<String> titleList(List<Memo> memolist) {
return memolist.map((e) => e.title).toList();
}
static List<String> contentList(List<Memo> memolist) {
return memolist.map((e) => e.content).toList();
}
static List<String> timeList(List<Memo> memolist) {
return memolist
.map((e) => DateFormat('yyyy-MM-dd HH:mm:ss').format(e.time))
.toList();
}
}
memo_view_model.dart
import 'package:flutter/material.dart';
import 'package:mvvm_example/models/memo.dart';
import 'package:shared_preferences/shared_preferences.dart';
class MemoViewModel extends ChangeNotifier {
List<Memo> _memolist = [];
List<Memo> get memolist => _memolist;
MemoViewModel() {
getMemo();
}
Future<void> getMemo() async {
final prefs = await SharedPreferences.getInstance();
_memolist = Memo.listFromString(
prefs.getStringList('title') ?? [],
prefs.getStringList('content') ?? [],
prefs.getStringList('time') ?? []);
notifyListeners();
}
void updateMemo({Memo? oldMemo, Memo? newMemo}) {
if (newMemo != null) {
_memolist.remove(oldMemo);
_memolist.insert(0, newMemo);
}
_saveMemo();
}
void removeMemo(Memo memo) {
_memolist.remove(memo);
_saveMemo();
}
Future<void> _saveMemo() async {
final prefs = await SharedPreferences.getInstance();
prefs.setStringList('title', Memo.titleList(memolist));
prefs.setStringList('content', Memo.contentList(memolist));
prefs.setStringList('time', Memo.timeList(memolist));
notifyListeners();
}
}
memo_view.dart
import 'package:flutter/material.dart';
import 'package:mvvm_example/models/memo.dart';
import 'package:mvvm_example/viewmodels/memo_view_model.dart';
import 'package:mvvm_example/views/memo_detail_view.dart';
import 'package:provider/provider.dart';
class MemoView extends StatelessWidget {
const MemoView({super.key});
@override
Widget build(BuildContext context) {
MemoViewModel viewModel = Provider.of<MemoViewModel>(context);
return Scaffold(
appBar: AppBar(
title: const Text('Memo'),
centerTitle: true,
),
body: GridView.builder(
itemCount: viewModel.memolist.length,
padding: const EdgeInsets.all(20),
gridDelegate: const SliverGridDelegateWithFixedCrossAxisCount(
crossAxisCount: 3,
mainAxisSpacing: 8,
crossAxisSpacing: 8,
childAspectRatio: 3 / 4,
),
itemBuilder: (context, idx) =>
memoCard(context, viewModel.memolist[idx]),
),
floatingActionButton: FloatingActionButton(
onPressed: () async {
Memo? newMemo = await Navigator.push(
context, pageRouteBuilder(const MemoDetailView()));
viewModel.updateMemo(newMemo: newMemo);
},
child: const Icon(Icons.add),
),
);
}
Widget memoCard(BuildContext context, Memo memo) {
MemoViewModel viewModel = Provider.of<MemoViewModel>(context);
return InkWell(
onTap: () async {
Memo? newMemo = await Navigator.push(
context, pageRouteBuilder(MemoDetailView(memo: memo)));
viewModel.updateMemo(oldMemo: memo, newMemo: newMemo);
},
child: Card(
child: Padding(
padding: const EdgeInsets.all(8.0),
child: Column(
crossAxisAlignment: CrossAxisAlignment.start,
children: [
Row(
children: [
Expanded(
child: Text(
memo.title,
style: const TextStyle(
fontSize: 16,
fontWeight: FontWeight.bold,
),
overflow: TextOverflow.ellipsis,
),
),
GestureDetector(
onTap: () => viewModel.removeMemo(memo),
child: const Icon(
Icons.close,
size: 16,
),
),
],
),
Expanded(
child: Text(
memo.content,
style: const TextStyle(
color: Colors.grey,
fontWeight: FontWeight.w300,
),
maxLines: 2,
overflow: TextOverflow.ellipsis,
),
),
],
),
),
),
);
}
PageRouteBuilder<Memo> pageRouteBuilder(Widget page) {
return PageRouteBuilder(
pageBuilder: (_, __, ___) => page,
transitionDuration: const Duration(milliseconds: 200),
reverseTransitionDuration: const Duration(milliseconds: 200),
opaque: false,
transitionsBuilder: (_, animation, __, child) {
return SlideTransition(
position: animation.drive(
Tween(
begin: const Offset(1.0, 0.0),
end: Offset.zero,
).chain(CurveTween(curve: Curves.ease)),
),
child: child,
);
},
);
}
}
memo_detail_view.dart
import 'package:flutter/material.dart';
import 'package:mvvm_example/models/memo.dart';
import 'package:intl/intl.dart';
class MemoDetailView extends StatefulWidget {
const MemoDetailView({super.key, this.memo});
final Memo? memo;
@override
State<MemoDetailView> createState() => _MemoDetailViewState();
}
class _MemoDetailViewState extends State<MemoDetailView> {
late final TextEditingController title, content;
@override
void initState() {
super.initState();
title = TextEditingController(text: widget.memo?.title);
content = TextEditingController(text: widget.memo?.content);
}
@override
void dispose() {
title.dispose();
content.dispose();
super.dispose();
}
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
actions: [
IconButton(
onPressed: () {
if (title.text.isEmpty) {
ScaffoldMessenger.of(context).showSnackBar(SnackBar(
duration: const Duration(seconds: 1),
content: Row(
children: const [
Icon(
Icons.close,
color: Colors.red,
),
Text('제목을 입력해주세요'),
],
),
));
} else {
Navigator.pop(
context,
Memo(
title: title.text,
content: content.text,
time: DateTime.now(),
));
}
},
icon: const Icon(Icons.check),
),
],
),
body: Padding(
padding: const EdgeInsets.fromLTRB(20, 20, 20, 0),
child: Column(
children: [
form(
controller: title,
hintText: '제목',
),
const SizedBox(height: 12),
Expanded(
child: form(
controller: content,
maxLines: null,
hintText: '내용',
),
),
Container(
height: 60,
alignment: Alignment.center,
child: Text(DateFormat('yyyy.MM.dd HH:mm')
.format(widget.memo?.time ?? DateTime.now())),
),
],
),
),
);
}
Widget form({
TextEditingController? controller,
int? maxLines = 1,
required String hintText,
}) {
return Container(
padding: const EdgeInsets.symmetric(horizontal: 8),
decoration: BoxDecoration(
border: Border.all(color: Colors.blue),
borderRadius: BorderRadius.circular(8),
),
child: TextFormField(
controller: controller,
maxLines: maxLines,
decoration: InputDecoration(
border: InputBorder.none,
hintText: hintText,
),
),
);
}
}
마무리
지금까지 MVVM 패턴에 대해 알아보고 이를 적용해 간단한 메모 앱까지 만들어 보았습니다. MVVM 패턴을 처음 접하는 분들께 도움이 되었길 바라며 마치겠습니다.

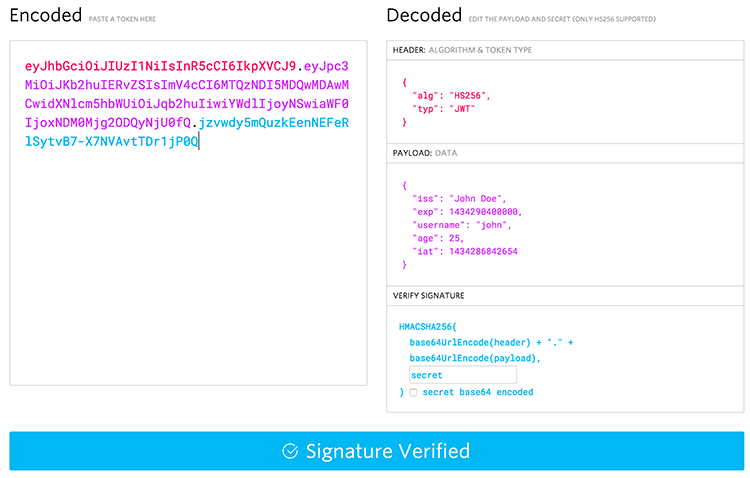
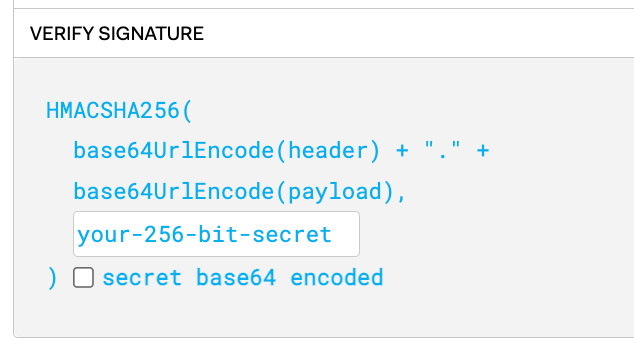 header를 디코딩한 값 + “.” + payload를 디코딩한 값을 위처럼 합치고 이를 your-256-bit-secret, 즉, 서버가 가지고 있는 개인키를 가지고 암호화한 것이 Signature입니다. 따라서 signature는 서버에 있는 개인키로만 암호화를 풀 수 있으므로 다른 클라이언트는 임의로 Signature를 복호화할 수 없습니다.
header를 디코딩한 값 + “.” + payload를 디코딩한 값을 위처럼 합치고 이를 your-256-bit-secret, 즉, 서버가 가지고 있는 개인키를 가지고 암호화한 것이 Signature입니다. 따라서 signature는 서버에 있는 개인키로만 암호화를 풀 수 있으므로 다른 클라이언트는 임의로 Signature를 복호화할 수 없습니다.